Browser Extension
Overview
KindleEar provides a Chrome/Edge browser extension that not only offers bookmarklet functionality but also includes a feature for generating web scraping recipes without writing any code. With this feature, you don't need to understand programming or write code; just a few clicks can generate a Recipe file that KindleEar can use.
This is particularly useful for pushing content from structured websites that don't provide RSS feeds, such as news or forum sites. Nowadays, most websites use templates to generate pages dynamically, so this should work for the majority of website content for scheduled scraping.
For many websites that heavily use JavaScript to dynamically generate pages (where the content rendered by the browser differs from the content in the HTML), using this extension may require some background knowledge. It's best to have some basic knowledge of HTML/JavaScript, but nonetheless, you can at least use it to get started in scripting.
Installation
Search for "KindleEar" in the Chrome/Edge Web Store.
Alternatively, here is
Features Overview
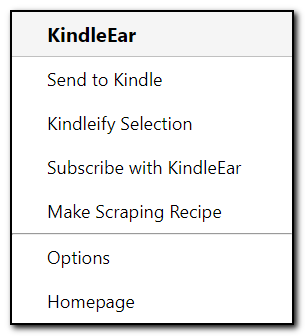
-
Send to Kindle: Directly calls the url2book endpoint of your KindleEar web app to push the current page you're browsing to Kindle. If you select some content (which can include images), only the selected content will be pushed; otherwise, the entire page will be pushed.
-
Kindleify Selection: Similar to "Send to Kindle", but this feature uses Gmail service to send to KindleEar's email module for transfering. If deployed on GAE, the email address is read@appid.appspotmail.com. If deployed on other platforms, postfix or other mail servers need to be used; otherwise, this feature will not work. One difference from the previous option is that this feature only sends text if selecting some content, excluding images.
-
Subscribe with KindleEar: If you open an RSS subscription link (usually in XML format), you can click this menu to directly fill the title and url into KindleEar's Feeds page, only for super lazy people.
-
Make Scraping Recipe: This menu is the main focus of this document, explained in the sections below.
-
Options: If you want to use other functions besides "Make Scraping Recipe", please fill in the relevant KindleEar website information on the options page first.
-
Homepage: Links to the KindleEar homepage.
Instructions for "Make Scraping Recipe"
Let's explain and illustrate the use of this tool with an actual website.
CNN, a world-leading news website that doesn't provide RSS feeds, will be our target.
CNN has many sections, let's open CNN World, then launch the extension's "Make Scraping Recipe" tool.
The tool's gui shows it's in the first step, where you need to click article links to generate the article list on the main page.
In the top right corner of the dialog, there's a dropdown for depth. This value indicates how many levels of HTML DOM structure we'll use to pick the elements we need. If you find too many or too few articles/content in result, you can increase or decrease this depth, or directly edit the selectors to remove some rules.
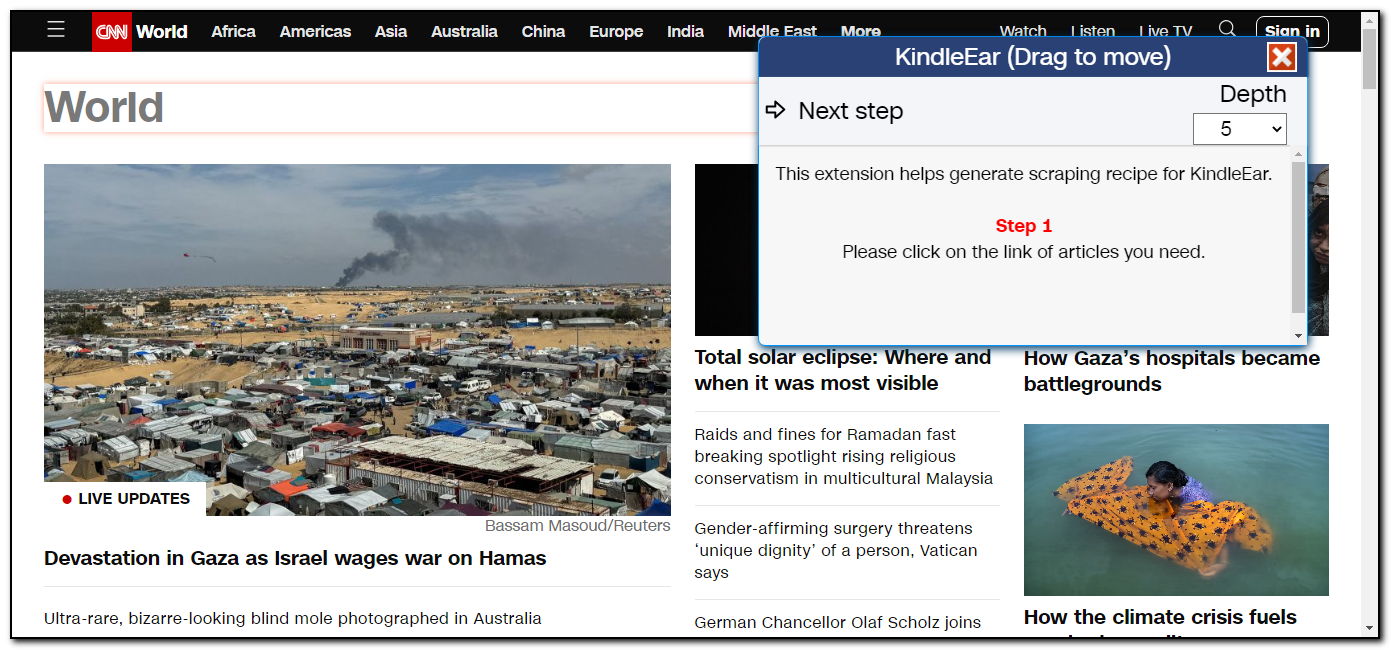
By clicking the link "Devastation in Gaza as Israel wages war on Hamas" on the webpage, the extension shows it found an article.
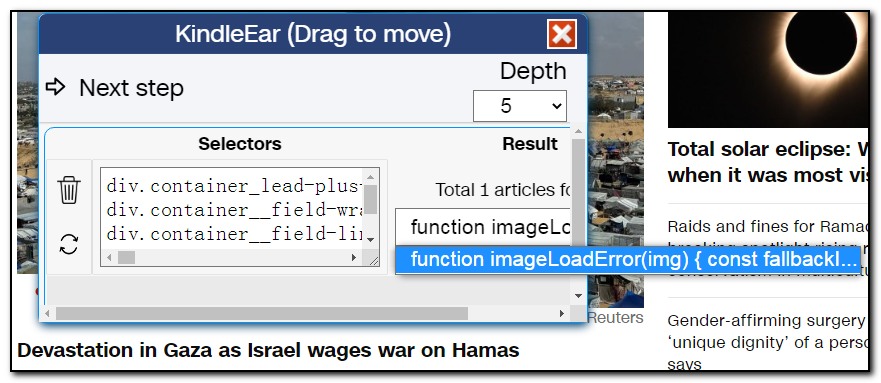
However, the title is incorrect due to a JavaScript error on CNN's side, but for now, let's ignore it. Now, since we only found one article, we continue clicking other links. This time, we find 63 articles, which should be correct.
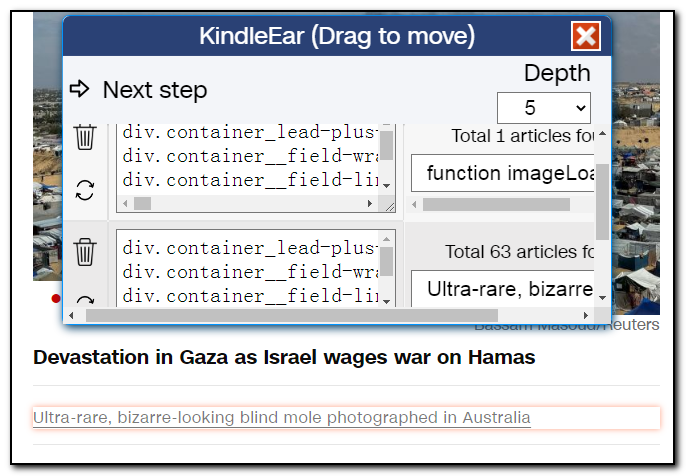
Let's delete the first row by clicking the trash icon. Then, we select an article randomly from the dropdown and click "Next step", and the extension will open the selected article in a new tab.
Note: Why do we delete the first item? There's another reason: the structure of the first item's content page is different from others. If you need the first article, create a separate scraping script following the same steps.
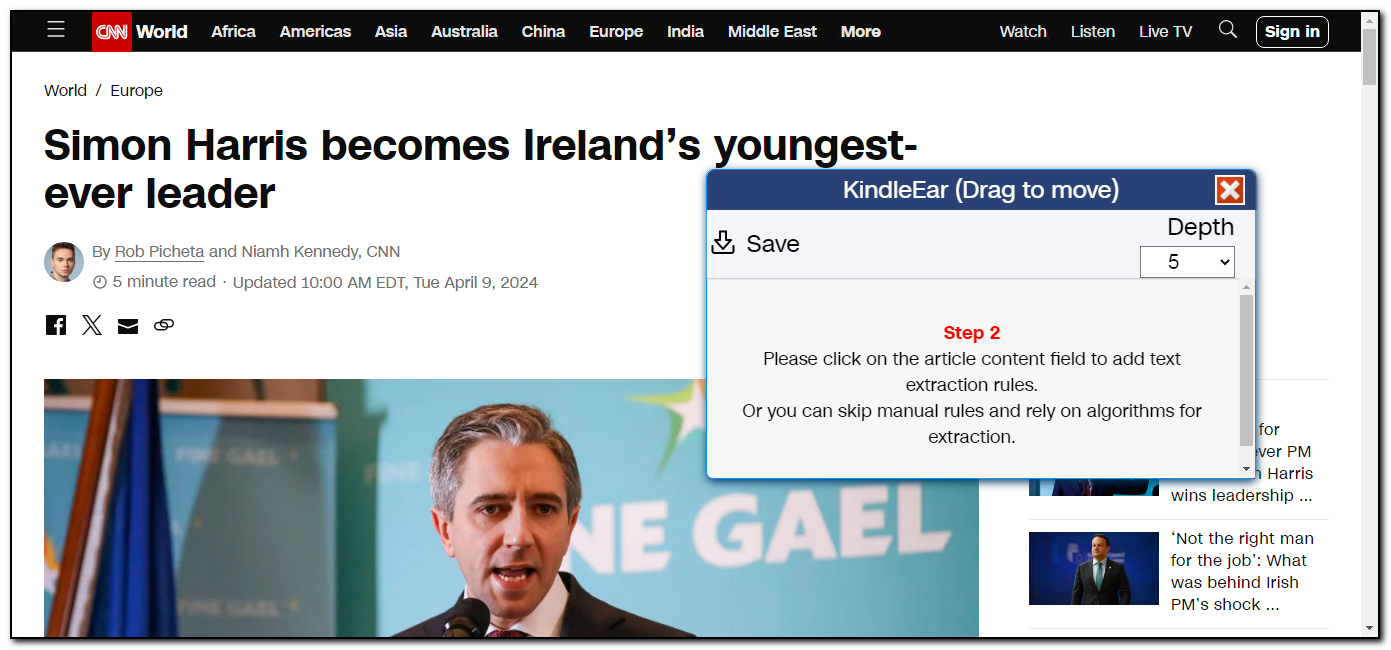
The extension now shows it's in the second step. You can click on the text area on the page to add text extraction rules or leave it to KindleEar to automatically extract. If you're using the automatic extraction algorithm, click "Save" in the top left corner to save the generated Python file locally.
My advice is to test with the automatic extraction algorithm first; if it's unsatisfactory, then add manual rules.
To illustrate the usage, let's add manual rules now. We move the mouse on the webpage to see if the mouse shadow perfectly covers the content we need. After testing, the webpage doesn't fit well with the shadow, either too large or too small. So, let's start by adding a rule for the title (you can skip adding a title rule and let KindleEar add it automatically during scraping). Then, we find a shadow that just completely covers the main content. With these two rules, we can fully extract the article content.
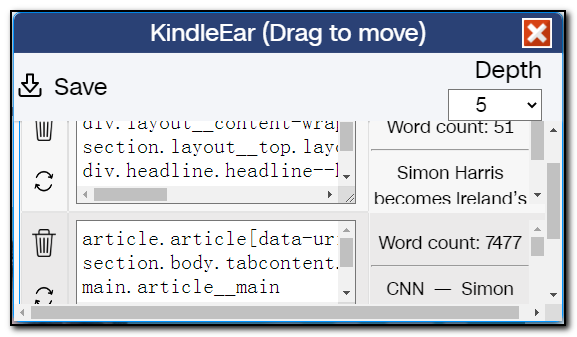
Clicking "Save" in the top left corner to save the script locally and open your deployed KindleEar website. Use the "Upload Custom Recipe" feature on the "Feeds" page to upload it to KindleEar for subscription and testing. If the test results are unsatisfactory, come back to either recreate or manually modify the saved script file.
The automatically generated script failed in the first test as it couldn't find article links, resulting in a failed push.
This is because CNN's website uses JavaScript to add too many attributes to links, which don't exist in the HTML content. So, we edit the script file to modify the CSS selector for the last line in url_extract_rules. Since this line is too long, looking at the code below, just the last line in the array is that long, with a total of 3 classes and 20 attributes
a.container__link.container__link--type-article.container_lead-plus-headlines__link[href][data-link-type][data-zjs][data-zjs-cms_id][data-zjs-canonical_url][data-zjs-zone_id][data-zjs-zone_name][data-zjs-zone_type][data-zjs-zone_position_number][data-zjs-zone_total_number][data-zjs-container_id][data-zjs-container_name][data-zjs-container_type][data-zjs-container_position_number][data-zjs-container_total_number][data-zjs-card_id][data-zjs-card_name][data-zjs-card_type][data-zjs-card_position_number][data-zjs-card_total_number]
Let's delete the class names and properties of tag A. After the modification, the array looks like this:
#modified code, the class names and properties of tag A are deleted.
url_extract_rules = [[
"div.container_lead-plus-headlines__cards-wrapper",
"div.container__field-wrapper.container_lead-plus-headlines__field-wrapper",
"div.container__field-links.container_lead-plus-headlines__field-links",
"div.card.container__item.container__item--type-media-image",
"a",]]
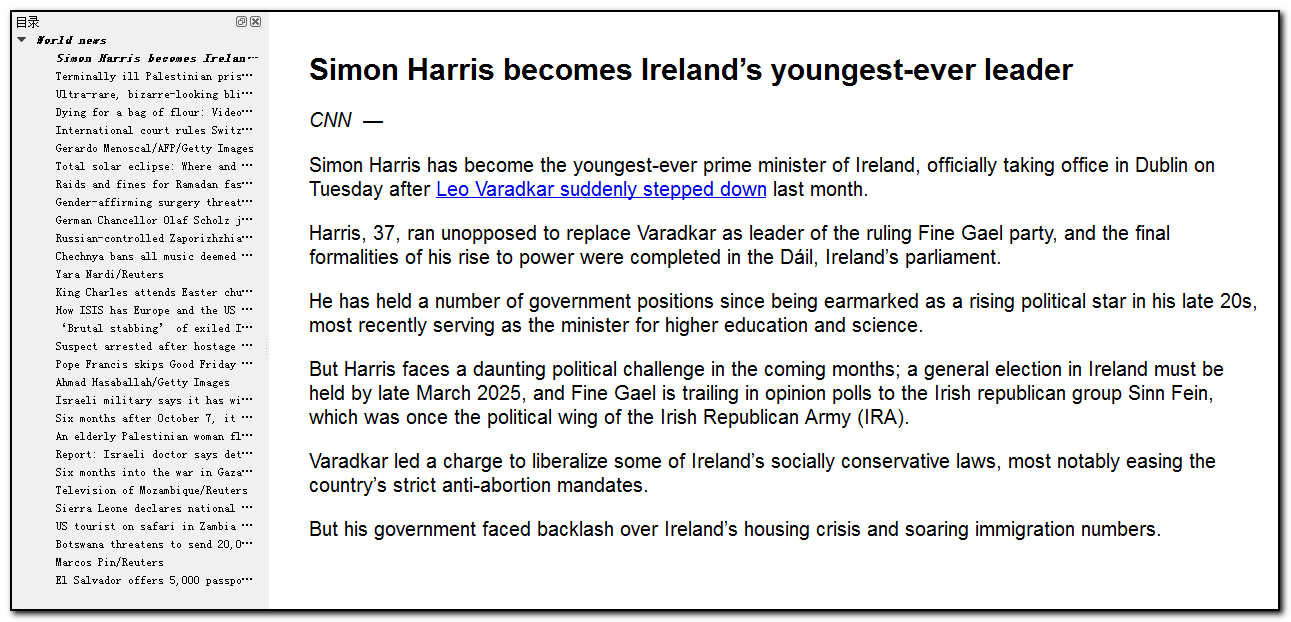
After re-uploading and retesting, it succeeded; the table of content is normal, and the article content is complete.
-
Manual modifications to rules can be done after saving to the script file or directly within the extension's dialog. One CSS selector rule per line. After modification, click the refresh button on the left to confirm that the CSS selector rule is correct before proceeding to the next step.
-
Simplicity is key; overly complex matters are often incorrect. If you're unfamiliar with HTML/CSS, a rule of thumb is to delete part or all of a rule if you notice an exceptionally long string or if there are numbers within the string. Deletion should be done with the dot and square brackets as boundaries. It's better to delete too much than too little. If it's not suitable, simply regenerate the rules with a few clicks of the mouse.
-
For some web pages, the JavaScript may be too complex, resulting in our tool's dialog not automatically popping up in the second step. In such cases, just reopen the extension menu and click "Make Scraping Recipe" to bring up the interface.
-
The generated script is tailored to the current website structure. However, once the website undergoes changes, the script becomes obsolete, a new script needs to be generated. This is the primary reason for developing this tool: many of Calibre's built-in Recipes become unusable due to website changes. Continuously updating these Recipes by manually analyzing website code is a significant and unsustainable effort.
-
If further modifications and debugging are necessary, you can hold Ctrl while saving the code. This will add a stub and execution code to the saved script, allowing for easy debugging locally without relying on KindleEar. Only Python/requests/bs4 installation is required (
pip install requests beautifulsoup4). After executing the code, index.html and the HTML of the first two articles will be generated in the same directory. This debugging code file cannot be directly uploaded to KindleEar. After debugging is complete, the code from the CustomRecipe section needs to be copied into a new file and uploaded to KindleEar.