浏览器扩展程序
概述
KindleEar提供一个Chrome/Edge浏览器扩展程序,除了提供bookmarklet的功能外,特别的还有一个无代码生成爬虫脚本的功能。
使用此功能,你不需要懂编程,不需要编写代码,点击几下就可以生成一个KindleEar能用的Recipe文件,特别适用于推送一些不提供RSS订阅的结构化网站,比如新闻类/论坛类等。
时至今日,大部分网站的后台都使用某些模板自动生成网页,所以应该能适用于大部分网站内容的定时抓取。
对于很多大量使用javascript动态生成网页的网站(浏览器呈现的内容和html里面的内容不一致),使用此扩展程序可能会有一些挑战,最好有一些html/javascript的基础知识,不管如何,至少可以用它来开个头或协助你完成脚本。
安装
在Chrome/Edge应用商店搜索 "KindleEar"。
或者使用
Chrome直达链接
界面介绍
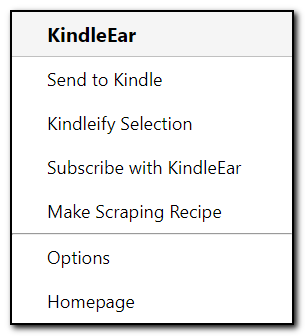
-
发送到 Kindle 直接调用您搭建的KindleEar的 url2book 端点功能来实现将当前您正在浏览的网页推送到Kindle,如果选择了部分网页内容(可以包含图像),则只推送选择的内容,否则会推送整个网页。
-
选择内容发送到 Kindle 和 "发送到 Kindle" 功能类似,只是此选项使用gmail的发送邮件功能发送到KindleEar的邮件模块,如果部署在GAE上,邮件地址为 read@appid.appspotmail.com ,部署到其他平台需要postfix或其他邮件服务器搭配使用,否则此功能无效。
此功能和上面的选项还有一个区别,这个功能选择部分内容后只发送文本内容,不包含图像。 -
在 KindleEar 中订阅 如果您打开了一个RSS订阅链接(一般为xml格式),可以点击此菜单直接将链接和标题填写到KindleEar的添加自定义RSS页面,超级懒人必备。
-
制作爬虫脚本 这个菜单是是我写这篇文档的主要意图,在下面的章节介绍。
-
选项 如果要使用除了 "制作爬虫脚本" 的其他功能,请先在选项页填写相关的KindleEar网站信息。
-
主页 链接到github的 KindleEar主页。
制作爬虫脚本步骤说明
没有实际操作的文档空洞无力,既然这样,我们就以一个实际的网站来解释和说明此工具的使用。
我们选择一个不提供RSS订阅的世界顶级的新闻网站 CNN 。
CNN有很多栏目,随便选择一个,打开 CNN World,然后启动扩展程序的"制作爬虫脚本"工具。
工具主界面显示,现在处于第一步,需要通过点击文章链接来生成主页的文章列表。
主界面右上角有一个深度的下拉选项,这个数值是表示我们通过多少层的HTML结构来限定一个我们需要的元素,如果找到的文章/内容太多了,可以增加这个深度,如果找到的文章/内容太少了,可以减小这个深度,或直接编辑选择器,删除部分限制符。
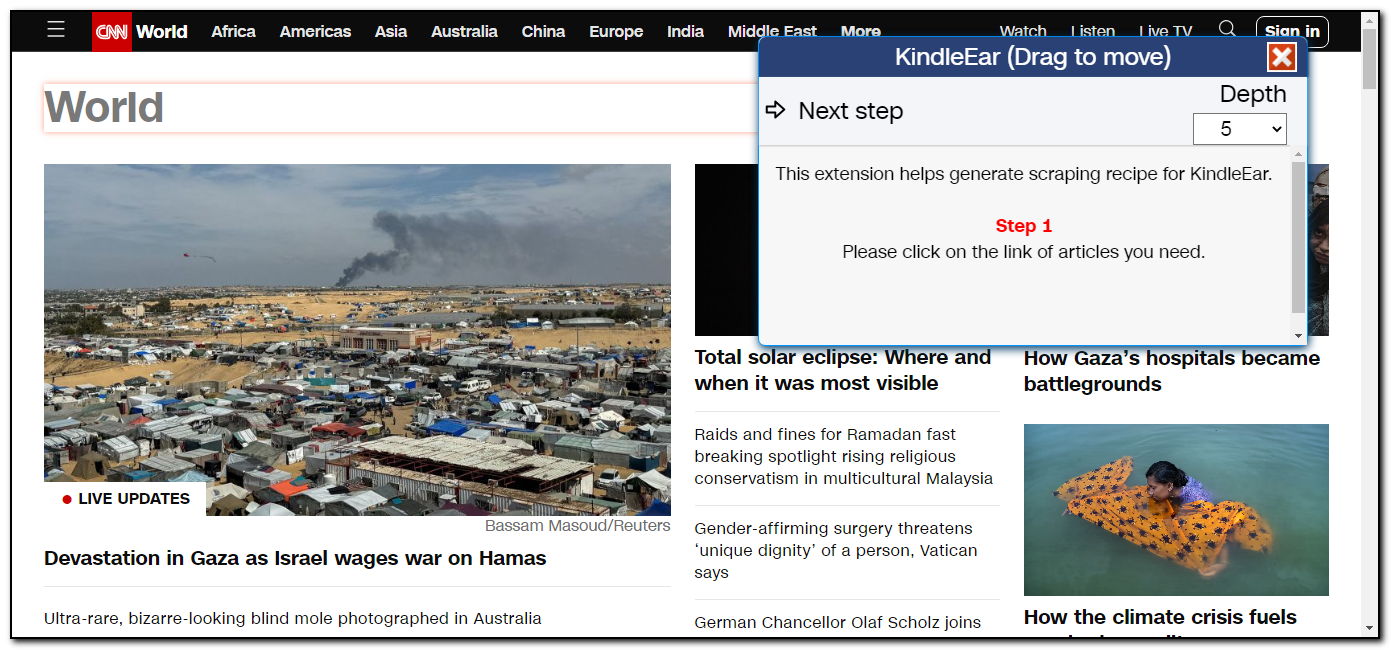
我们点击主页的链接 "Devastation in Gaza as Israel wages war on Hamas",扩展程序主界面显示找到了一篇文章。
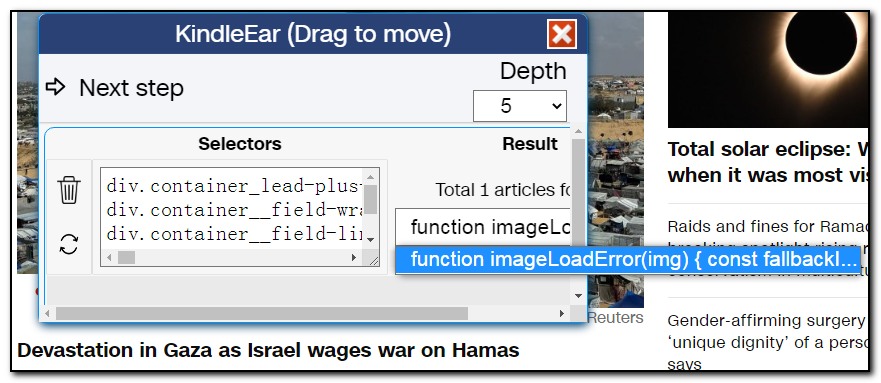
但是文章的标题不对,这个是因为cnn的javascript脚本出错了,暂不管它,现在问题是只找到一篇文章,所以我们继续点击其他链接,发现这次找到63篇文章,应该对了。
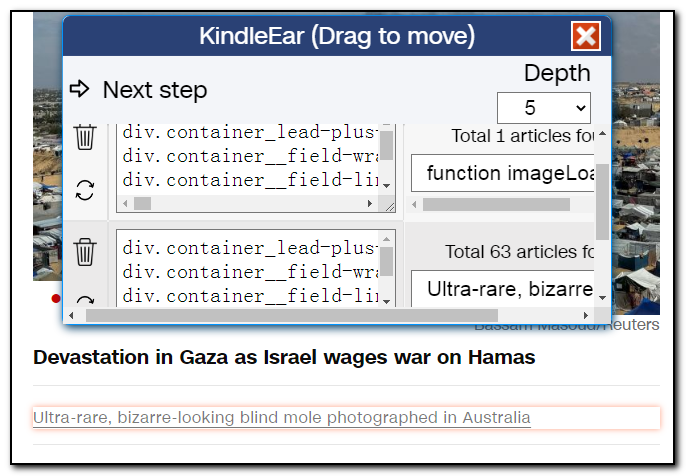
我们点击表格第一行左边的垃圾桶图标将第一行删除,然后在下拉框随便选择一篇文章,点击 "下一步",扩展程序会在一个新的tab上打开您选择的这篇文章。
注:我们为什么要删掉第一项,还有一个原因,因为在这里第一项链接打开的网页结构和其他的文章结构不一样,如需要第一项的文章,请另外创建一个单独的抓取脚本,方法步骤一样。
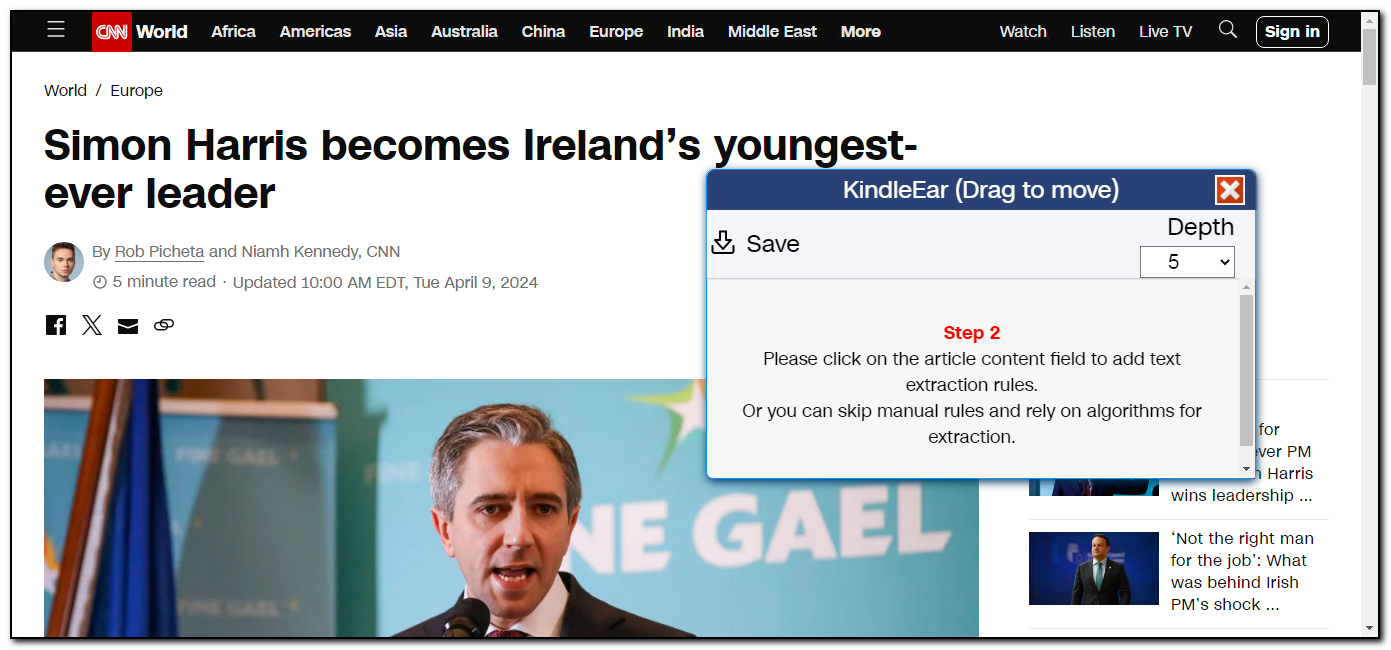
扩展程序的主页上显示当前处于第二步,可以点击页面上的文本区域添加文本提取规则,或者不添加规则,让KindleEar自动提取。如果使用自动提取算法,则现在就点击左上角的 "保存" 将生成的python文件保存到本地。
我的建议是先使用自动提取算法进行测试,自动提取算法不合意再选择手动添加规则。
为了说明使用方法,我们现在添加手动规则。
我们鼠标在界面上移动,看鼠标遮罩阴影能否刚好盖住我们需要的正文内容。经过测试,这个网页不行,遮罩要不太大要不太小。
所以我们先点击标题添加一个规则(你也可以不添加标题规则,让KindleEar抓取时再自动添加),下面的正文内容一个遮罩框刚好能完全覆盖,两个规则就能完整提取文章内容。
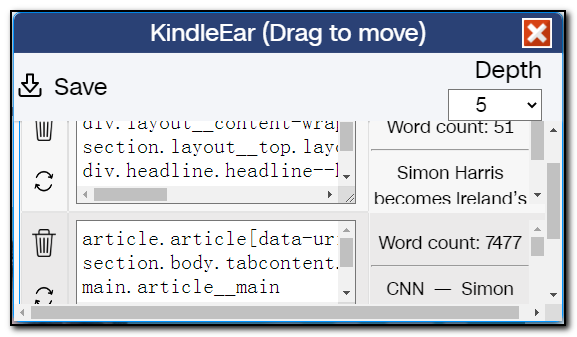
点击左上角保存按钮将脚本保存到本地后打开您部署的KindleEar网站,在我的订阅页面使用 "上传自定义 Recipe" 功能上传到KindleEar后即可订阅然后推送进行测试,如果测试结果不满意,再回来重新创建或手工修改刚保存的脚本文件。
这个自动生成的脚本文件经过第一次测试,无法找到文章链接,推送失败。
这是因为cnn网站使用javascript给链接添加了很多属性,而这些属性在html内容中并不存在,所以我们编辑脚本文件,修改url_extract_rules最后一行链接a的CSS选择器,因为这一行最长,长的不合常理,看下面代码,只是数组中的最后一行就有那么长,共3个class,20个属性:
a.container__link.container__link--type-article.container_lead-plus-headlines__link[href][data-link-type][data-zjs][data-zjs-cms_id][data-zjs-canonical_url][data-zjs-zone_id][data-zjs-zone_name][data-zjs-zone_type][data-zjs-zone_position_number][data-zjs-zone_total_number][data-zjs-container_id][data-zjs-container_name][data-zjs-container_type][data-zjs-container_position_number][data-zjs-container_total_number][data-zjs-card_id][data-zjs-card_name][data-zjs-card_type][data-zjs-card_position_number][data-zjs-card_total_number]
我们只保留标签名(或者干脆删除整行都可以),修改后的数组如下:
#modified code, the class names and properties of tag A are deleted.
url_extract_rules = [[
"div.container_lead-plus-headlines__cards-wrapper",
"div.container__field-wrapper.container_lead-plus-headlines__field-wrapper",
"div.container__field-links.container_lead-plus-headlines__field-links",
"div.card.container__item.container__item--type-media-image",
"a",]]
重新上传,重新推送测试,这回成功了,文章列表正常,文章内容完整。
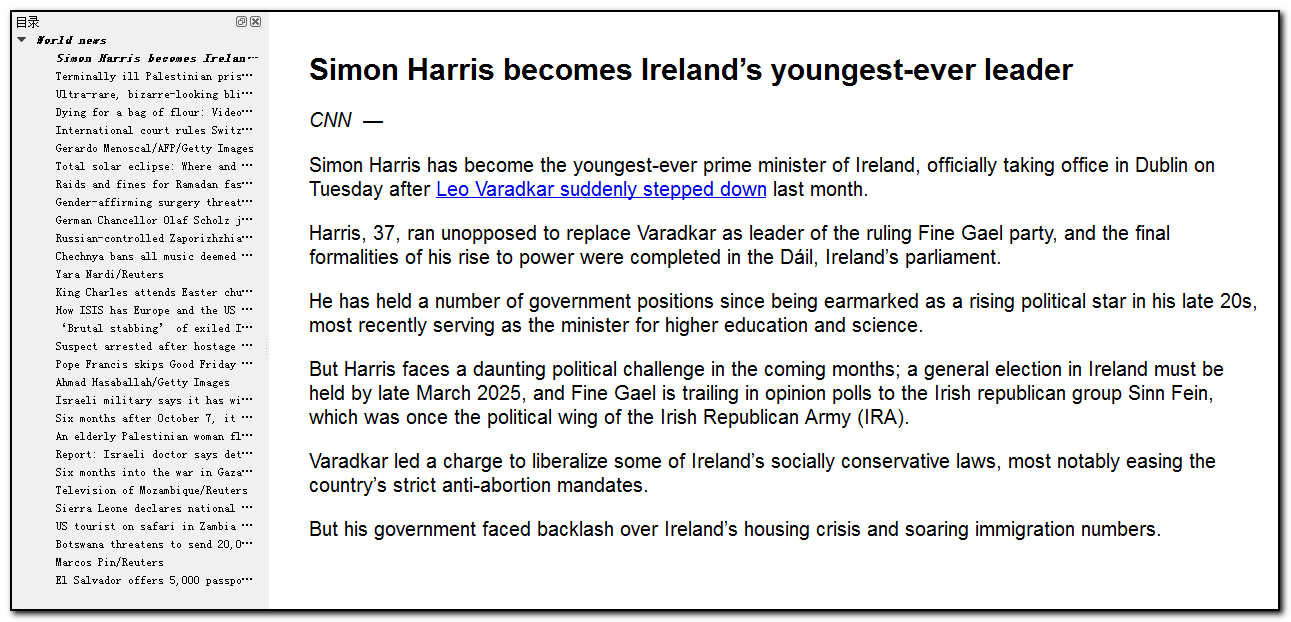
- 针对规则的手动修改可以在保存到脚本文件后进行,或者可以在扩展程序的界面上直接进行,一行一个CSS选择器规则,修改后点击对应行左边的刷新按钮,确认CSS选择器规则没有错误再进入下一步。
- 大道至简,太复杂的东西往往是错的。如果不懂HTML/CSS,经验法则是如果看到一个规则标签的字符串特别长,或字符串里面有一些数字,就可以删除一部分甚至整行删掉,删除时记住以点号和中括号为分界,反正不怕删多,不合适再重新生成即可,就点击几下鼠标的问题。
- 针对有些网页的javascript太过复杂导致第二步时我们的工具界面没有自动弹出,请在扩展菜单中重新点击"制作爬虫脚本"调出界面。
- 生成的这个脚本只是针对当前的网站结构,一旦网站改版,脚本就失效了,网站改版后需要重新生成新的脚本。这才是我开发这个工具的真实原因,因为Calibre的内置Recipe很多都因为网站改版而无法使用了,而通过手工分析网站代码而持续更新这些Recipe工作量可不小,没有可持续性。
- 如果需要更多的修改和调试,可以在保存代码时按住Ctrl,保存的脚本将增加一个桩和执行代码,可以方便的在本地不依赖KindleEar调试,只需要安装Python/requests/bs4(
pip install requests beautifulsoup4),代码执行后会在同一目录生成index.html和开始两篇文章的html。这个调试代码文件无法直接上传KindleEar,需要在调试完成后将CustomRecipe部分的代码拷贝出来再上传KindleEar。